

This morning I woke up to alerts from the unifi cloudkey telling me one of my wifi access points was disconnected. This was odd as this Access Point (AP) had been up and running fine ever since it had been configured.
I thought it might be a cable issue but then noticed that I could ping and SSH into it so it couldn't be a cable problem.
As this AP is connected to another AP (for cabling convenience) I rebooted that one and it came back up on the controller.
However, this was short-lived and it went back to being disconnected soon after.
Warning: Before getting into the details, if you try any of these steps please do so at your own risk. Messing with the internals of your networking gear could cause further issues if you make a mistake.
Investigating the AP
To investigate further, I ssh'd into the AP. To do this you can use the credentials for devices found under "Settings -> Site -> Device Authentication" for the old UI and "System Settings -> Device SSH Authentication" in the new UI.

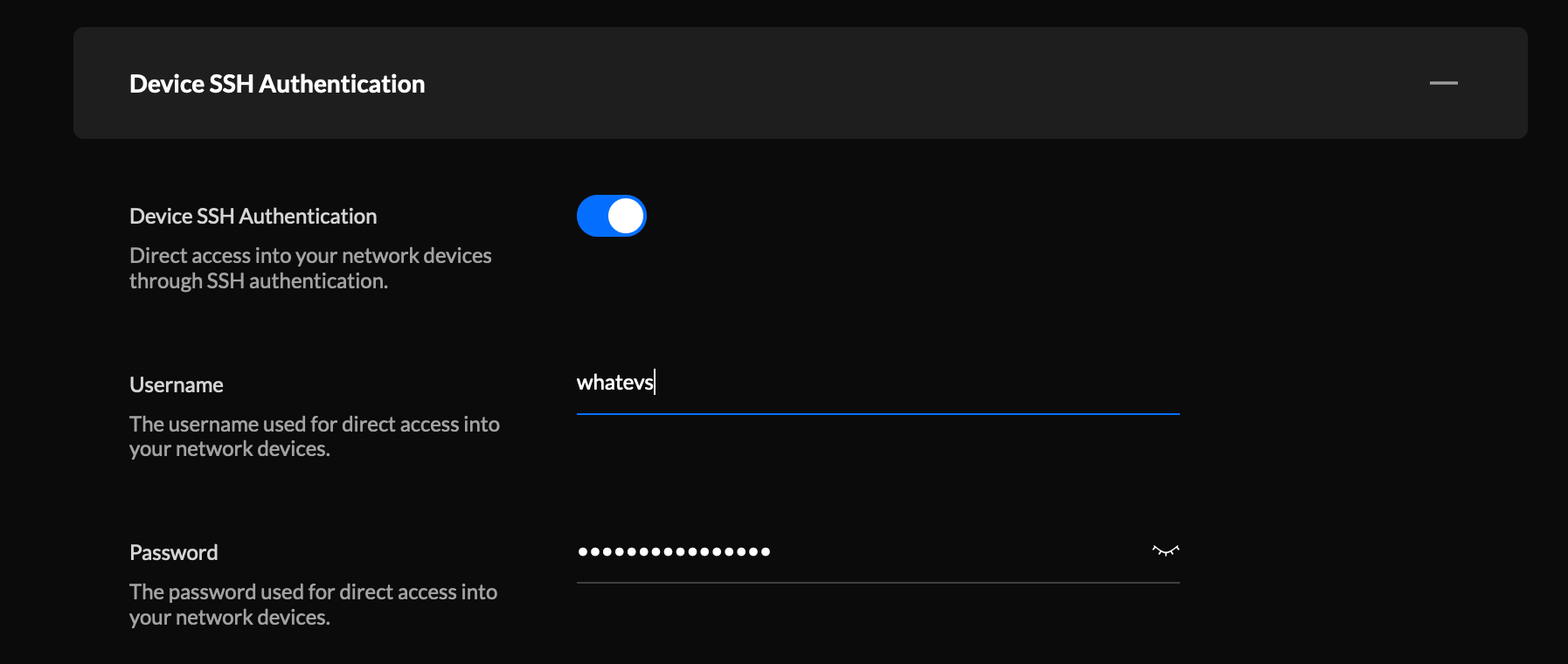
This also works with an SSH key if you'd already set one up.
One logged in I looked at the logs using tail -f /var/log/messages and found a lot of this, but that wasn't that useful
Wed Mar 24 14:55:21 2021 kern.warn kernel: [2807500.987781] osif_vap_init: Timeout waiting for vap to stop...continuing
Wed Mar 24 14:55:23 2021 user.err : mca-monitor[25605]: mca-proto.service(): Failed sending request to '/tmp/.mcad' - 'Connection refused'
Wed Mar 24 14:55:23 2021 user.info : mca-monitor[25605]: mca-monitor.do_monitor(): mcad.checkin is 588 ago (max=200)
Wed Mar 24 14:55:23 2021 user.notice syswrapper: kill-mcad. reason: mcad not respondingBut it wasn't clear what was happening.
Looking at the controller web interface the AP seemed to be trying to be adopted but kept failing.
Another oddity was the info command from the AP SSH session wasn't responding.
Investigating the controller logs
I then logged into the controller using SSH (Note: this uses a different SSH configuration to the one used by other devices).
Once logged in there I looked at the cloudkey logs using tail -f /usr/lib/unifi/logs/server.log
This showed up some logs related to issues with adoption:
<inform-15> ERROR inform - Inform Invalid for Device[xxx.xxx.xxx.xxx:48872], Bad packet magicAfter investigating those errors. I fairly quickly came to the conclusion the quickest way to get back up and running would be to reset the AP.
Resetting the AP
I started this process by resetting the AP over SSH using the following command:
set-defaultThis resets the AP to factory settings. Having done this you'll likely be booted from your SSH connection. To re-connect, you now need to use ubnt@xxx.xxx.xxx.xxx (use your ip address in place of the xxx.xxx.xxx.xxx) and the default password ubnt.
From there you should be able to start the adoption process with
set-inform http://xxx.xxx.xxx.xxx:8080/informWhere xxx.xxx.xxx.xxx is the controller ip.
This might be all you need, but in my case the AP seemed to be in an even tighter loop trying to be adopted and then failing.
Looking at the logs on the controller I found lots of this:
<inform-20> ERROR inform - invalid fingerprintFollowed by lots of output about the access point. This suggested the association between the AP and controller was broken so I needed a way to force the controller to "forget" the AP.
To do this required editing the mongo db. From the controller I ran:
mongo --shell --port 27117This opened a mongo shell. From here you need to switch the db and then find the AP by mac address (which should be displayed in the web ui):
> use ace
switched to db ace
> db.device.find({ 'mac' : 'xx:xx:xx:xx:xx:xx' })This should output some data on the AP. Then you can remove the AP with:
> db.device.remove({ 'mac' : 'xx:xx:xx:xx:xx:xx' })With that, the AP should be forgotten. From there I restarted the controller and if all's well you should find you are back at a "pending adoption" state for the errant AP. From here you can adopt it, re-instate the configuration and get back to something more interesting!
What I didn't find was a reason for the problem in the first place. If you know more details of why this happened based on the logs, and or a quicker way to resolve the problem without re-adoption please leave a comment and share your wisdom!