
I've been working on a few collaborative side-projects in my spare time which has ended up requiring several servers provisioned by a couple of different providers. The majority of them are Slicehost VMs but we also use Bytemark as a way of distributing risk for the unlikely event that the entire Slicehost network is suddenly unavailable, which means we have a fail-over for access to backups and a mirror of our entire wiki.
In order to manage the configuration of all of these machine I use Puppet to handle both server configuration and base-line software installation and set-up of all of our servers.
Here's a diagram of the rough layout:
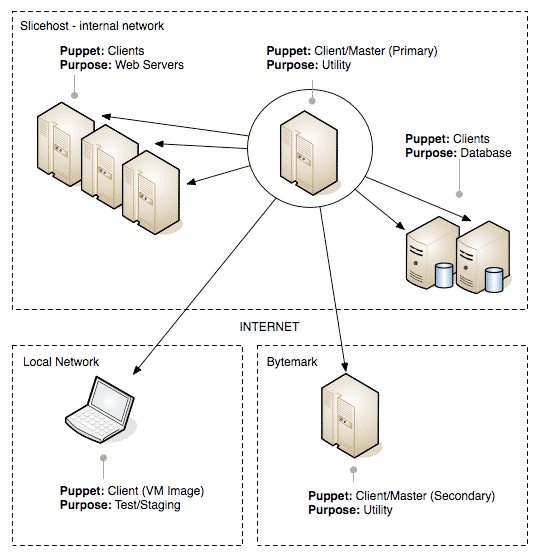
Puppet is a centralised server management tool written in Ruby which is available in Ubuntu stable repositories. It has two main components; a central service, the "puppetmaster" daemon and a client "puppet" service, which is installed on every machine that will take instructions from the puppetmaster. It's designed to apply configuration in an idempotent manner. Idempotence in this case means that repeatedly applying rules will always result in the same outcome. This is clearly a necessary requirement of anything that's managing server configuration.
Installation
I won't go into detailed set-up instructions here - but you will find comprehensive instructions on the Puppet wiki. Before you dive into installation read on to get more of a flavour for what's possible with Puppet and why it's awesome.Once you have installed the puppet master set-up you can configure a puppet client for each server you want to manage. Puppet has a neat system where each client is set-up with an SSL certificate so that all communication with the Puppetmaster is carried out securely.
Puppet Manifests
Manifests are the rules which define what puppet can do. Manifests contain classes that can be subclassed to form a set of rules with inheritance.Puppet is great at all system configuration tasks from managing configuration files, installing users, managing cron jobs, handling package installation etc. It does this by abstracting the various tools for different server operating systems so that if you write a manifest that installs apache for example it will use the correct package management software whether you run that rule against a Redhat, Ubuntu or Solaris client.
Nodes
The way I'm using puppet is to have a set of rules for each type of server that we run. E.g: webservers and utility servers. Each of this is a node.If I need to set-up more hardware for any reason I can order a slice which will be set-up in a matter of minutes. I can then install the puppet client, point it at the puppetmaster and configure it with the set of rules for a webserver and then within a couple of minutes that server will be running all of the necessary software (apache/mod_wsgi/django/python) along with all of our carefully tweaked configuration files.
This also means that we know that across all of our servers we are running the same configuration and software versions. If a global config manifest is updated we know that the next time that puppet client updates it will pull in the changes and we can also configure an event to restart relevant services on update too.
What I like about this is that I've only got to worry about setting things up once and then I can reproduce a stable set-up across as many servers as I want in a really short space of time. Previously I did all of these things manually which has two disadvantages, one; you spend lots of time carrying out the same set-up many times over for every machine. Secondly, you end up with things being set-up inconsistently and prone to human error.
Consistency is very important when it comes to security. Puppet can be used to provide hardening across all your machines by default which means that it's impossible to forget or overlook basic security services. When you put a box online it's secured by default.
As each node is configured separately you can also set-up test nodes in order to test configurations before rolling them out to front-line machines. This is much more re-assuring than just running updates and hoping for the best. Also, test nodes can be built from Virtual Machines on your local development machine so you don't even need to have slices for testing - albeit with the caveat that the hardware will of course be subtly different.
Types
Puppet has a concept of types which provide the means to handle all common configuration needs. For example there's package management for the installation/removal of specific packages. There's a type to handle user configuration. There's types for managing the creation of files/directories.When using puppet it's easy to get stuck and start relying on the Exec type to run shell-scripts so you can cover things you think puppet can't do. This is fine when necessary but all I'd say is make sure that puppet really can't do what you're doing with the shell-script as the built-in types are likely to be a lot more robust and well thought out.
What I don't like about Puppet
It should be pretty clear from what I've said that I think puppet rocks. However there are couple of small flys in the ointment. The first one is that puppet rules are written in a Domain Specific Language which is a bit like an amalgam between JSON and PHP. It's nice enough to use once you get used to it and has solid features like subclassing and functions, but personally I'd prefer it if it was Python. This of course is really unlikely to happen unless someone chooses to write a clone of Puppet in Python which pretty much amounts to wishful thinking on my part. Overall the puppet language doesn't really get in the way too much and I'm generally finding it to be a non-issue the more I use it.The second problem is the memory overhead of the client process. I don't run the clients on each server permanently (they default to looking for updates every 30 minutes) as I prefer to run updates manually via cron at a wider interval. This saves them sitting there taking up memory when they're not pulling updates from the master. Memory footprint may well have been addressed in more recent versions but I'm sticking to a policy of using the version available through the stable repo. Though I may consider using a PPA (Personal Package Archive) to provide a more recent version. (PPAs are a way of creating personal repositories for Ubuntu through launchpad.net)
Lastly, in the version I'm using if you make a mistake in the syntax of a puppet rule when you try and apply the rules to the target node nothing happens. When what you expect to happen doesn't, it's almost always a sign you've made syntactical errors. If you restart the puppet master and re-run the update on the client - only then will you see an error message relating to the problem. If you hit this problem and it annoys you then this recipe provides a way to know about syntax errors in your manifests.